

Published: May 6, 2025
Last modified: May 6, 2025
What is CVE?
The CVE program (Common Vulnerabilities and Exposures) is the most widely recognized database of known vulnerabilities.
Each CVE entry receives a unique identifier such as CVE-1900-1234, where “CVE-” is a prefix, 1900 is the year, and 1234 is the unique number assigned within that year. These identifiers help developers and security professionals consistently refer to specific vulnerabilities.
A typical entry (or rather the description) may read: “In XYZ product versions 1.1.2 to 1.1.7, an attacker could do something causing that kind of harm.”
How CVEs are assigned and modified
The CVE program has existed for over two decades and has evolved over time.
Today, CVE IDs are assigned by CNAs (CVE Numbering Authorities), which can be software vendors, security companies, or open-source foundations. Each CNA is responsible for maintaining CVE entries for the products in their scope – and is the only one allowed to assign or update them.
If you want to update a CVE entry, you must ask the responsible CNA.
What CVE entries contain — and what they don’t
CVE entries are required to include only a short human-readable description. CNAs do not have a requirement to include structured information such as affected product names, vendors, or versions.
This limitation makes it difficult for automated tools to process the data; remember that in an embedded systems, you often need to scan hundreds of packages.
NVD: Adding structure to CVEs
To compensate, the National Vulnerability Database (NVD) has traditionally added machine-readable details such as vendor and product tags, along with severity scores based on CVSS (Common Vulnerability Scoring System).
Tools like the Yocto Project’s cve-check depend on this enriched data for vulnerability scanning.
2024: NVD slowdown and partial recovery
In February 2024, NVD abruptly stopped processing new CVEs with this extra data. We do not know exactly why.
Since then, some activity has resumed, but the pace remains far below normal, with the backlog getting bigger. As an example: have a look at today’s (May 6th, 2025), NVD dashboard below: it has processed less than one-third of the CVEs from this week alone.
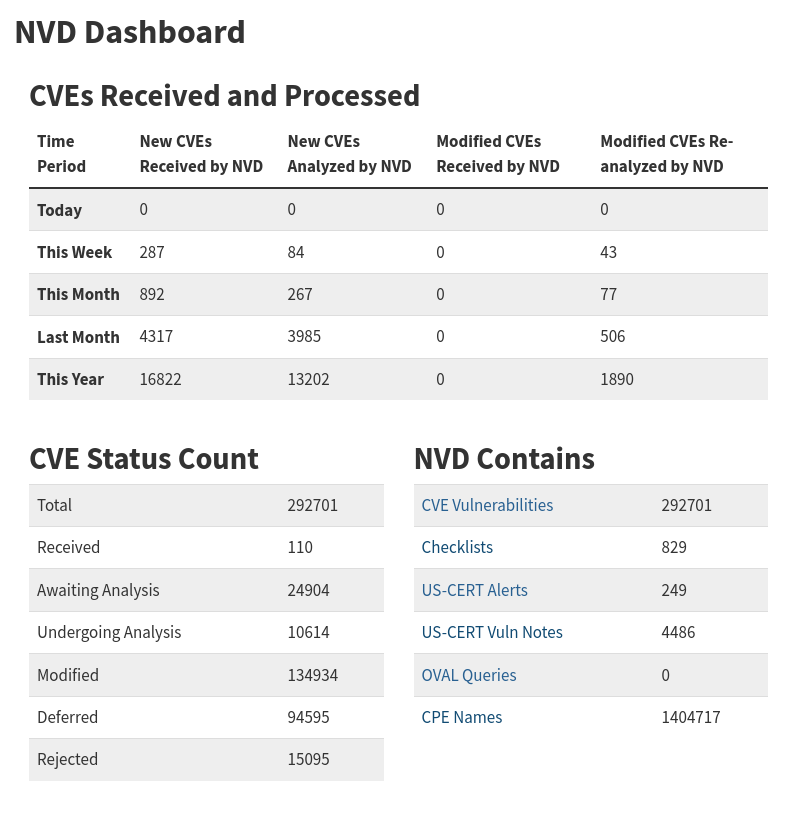
This has significant consequences: vulnerability scanners that rely on NVD data may miss many recent vulnerabilities, even if those issues are recorded in the CVE database itself.
2025: CVE program under pressure
In April 2025, a leaked memo suggested that the CVE program itself was facing internal challenges. Within hours, CISA (the US Cybersecurity and Infrastructure Security Agency) provided emergency funding to keep it running.
During that time, several new initiatives emerged:
- The CVE Foundation created by a part of the CVE Program board.
- A European CVE database (EUVD) that was in the works before, in the context of the CRA (Cyber Resilience Act).
- The Global CVE Allocation System (GCVE) based on the previous work from CIRCL Luxemburg.
- Vendors offering alternative databases or their own CVE ID assignment
At the moment, the CVE program continues to operate. We do not know what will happen beyond the current round of funding. While alternative solutions have appeared, none has emerged as a clear successor (according to what I see).
In the meantime, with the NVD backlog growing and CVE entries lacking structured data, the embedded industry lacks a free, accurate, and complete vulnerability database.
Rising noise in vulnerability reports
To complicate matters further, many open-source projects are receiving increasing numbers of automatically generated vulnerability reports – sometimes created by AI tools.
While spam (and CVE hunting – a subject for a separate post) has always been a problem in vulnerability reporting, these additional reports require manual review, which consumes time. And causes frustration.
Conclusion
Significant changes are coming to the vulnerability management space. Relying on a single vendor system (in this case: US-funded), both for CVE assignment and the enrichment by NVD, has revealed a structural problem. In addition, manual handling of CVEs does not scale.
At the same time, new regulations (like the CRA) require better security practices and rigorous vulnerability handling.
I am convinced that new solutions will emerge. There are multiple possibilities: better automatic processing of vulnerability data, new database standards, or even a bigger structural change (like a different way of handling vulnerabilities, not based on their enumeration).